Ra11y is an AI-powered translation tool bridging the communication gap between American Sign Language and English. It introduces a state-of-the-art multimodal transformer model to recognize and translate ASL gestures into natural English, and vice versa.
Artificial Intelligence & Accessibility
Python
TensorFlow
MediaPipe
OpenCV
The name "Ra11y" combines "rally"—a call to unite—and "a11y," short for accessibility. It's designed to make interactions more inclusive for Deaf and Hard-of-Hearing communities with real-time, two-way ASL–English translation in text and speech.
Millions rely on ASL as their primary language, but many services remain inaccessible. Existing tools often only support the alphabet, need paid APIs, or struggle with natural signing. Ra11y solves this with an offline, high-accuracy system that understands full ASL vocabulary.
ASL-to-English translation in real-time
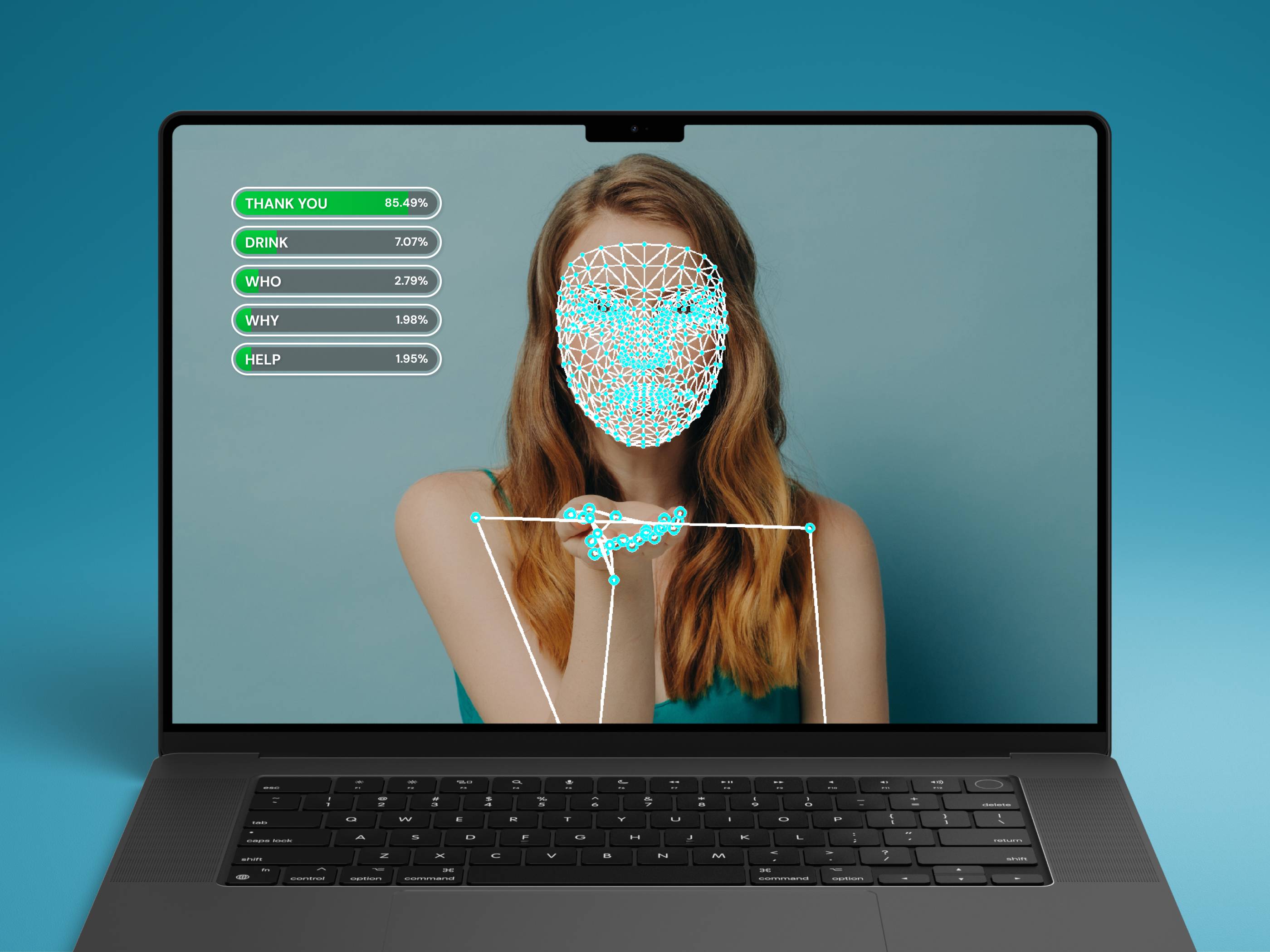
Ra11y analyzes live video to recognize ASL signs and translate them into English text or speech. It uses MediaPipe to track facial, hand, and body landmarks, combined with CNN image features for context. This multimodal approach improves accuracy even for subtle or similar signs.
Context-aware grammar correction
Because ASL doesn't have signs for every English word and often relies on context for meaning, Ra11y tracks sign history to understand sentence structure. This allows it to fill in missing words and adjust grammar, producing more natural and readable translations.

Dataset and feature extraction
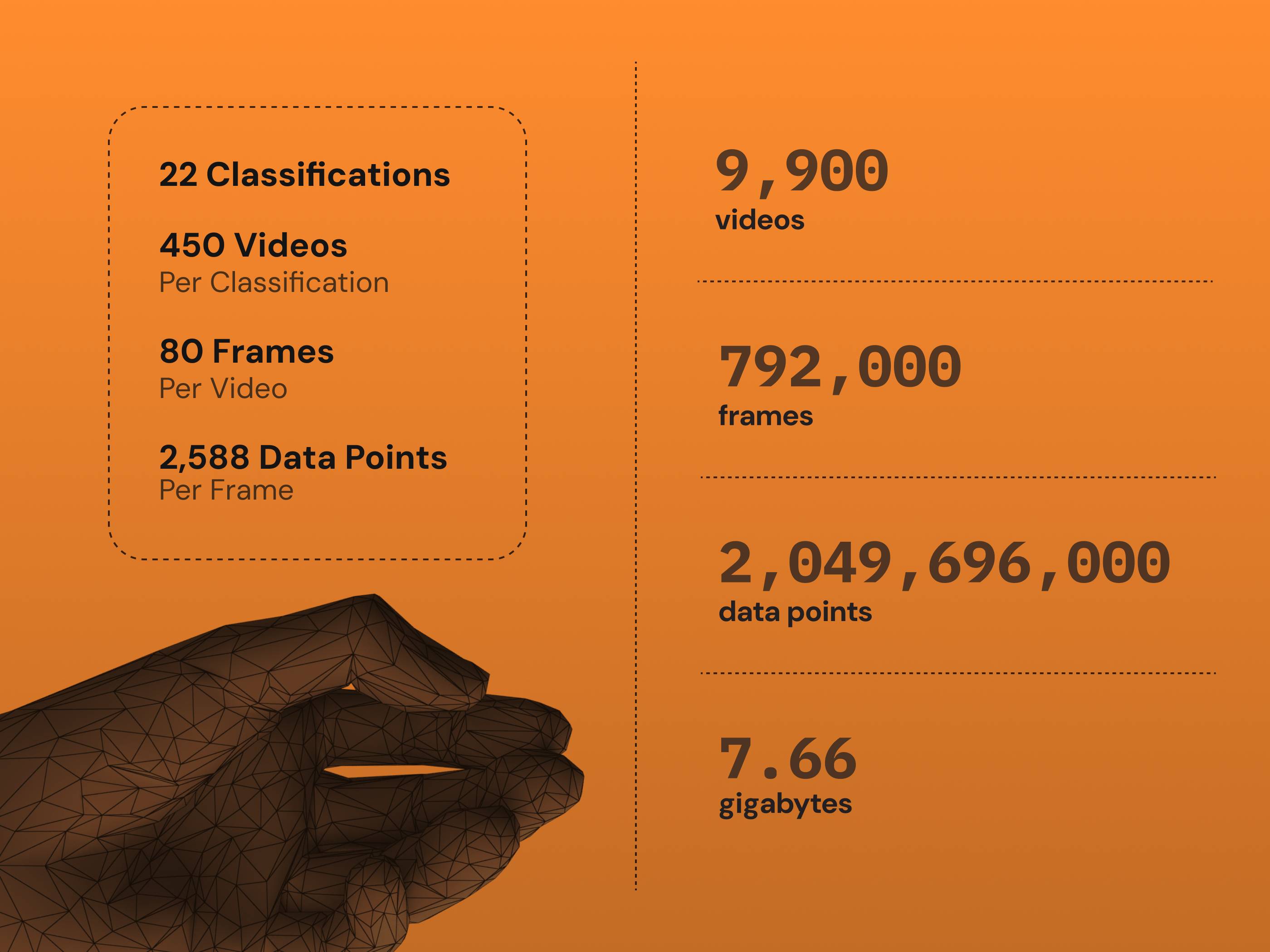
With no suitable open-source dataset, over 450 videos were recorded per sign, capturing 20–80 significant frames each. Shorter sequences were padded with masked values for consistency.
Each word is represented as a series of frame-by-frame sequences, combining skeletal keypoints (pose, face, hands) extracted via MediaPipe Holistic and CNN features from ResNet50 for added visual context. This multimodal approach improves recognition of even very similar signs.


Innovative multimodal approach using transformers
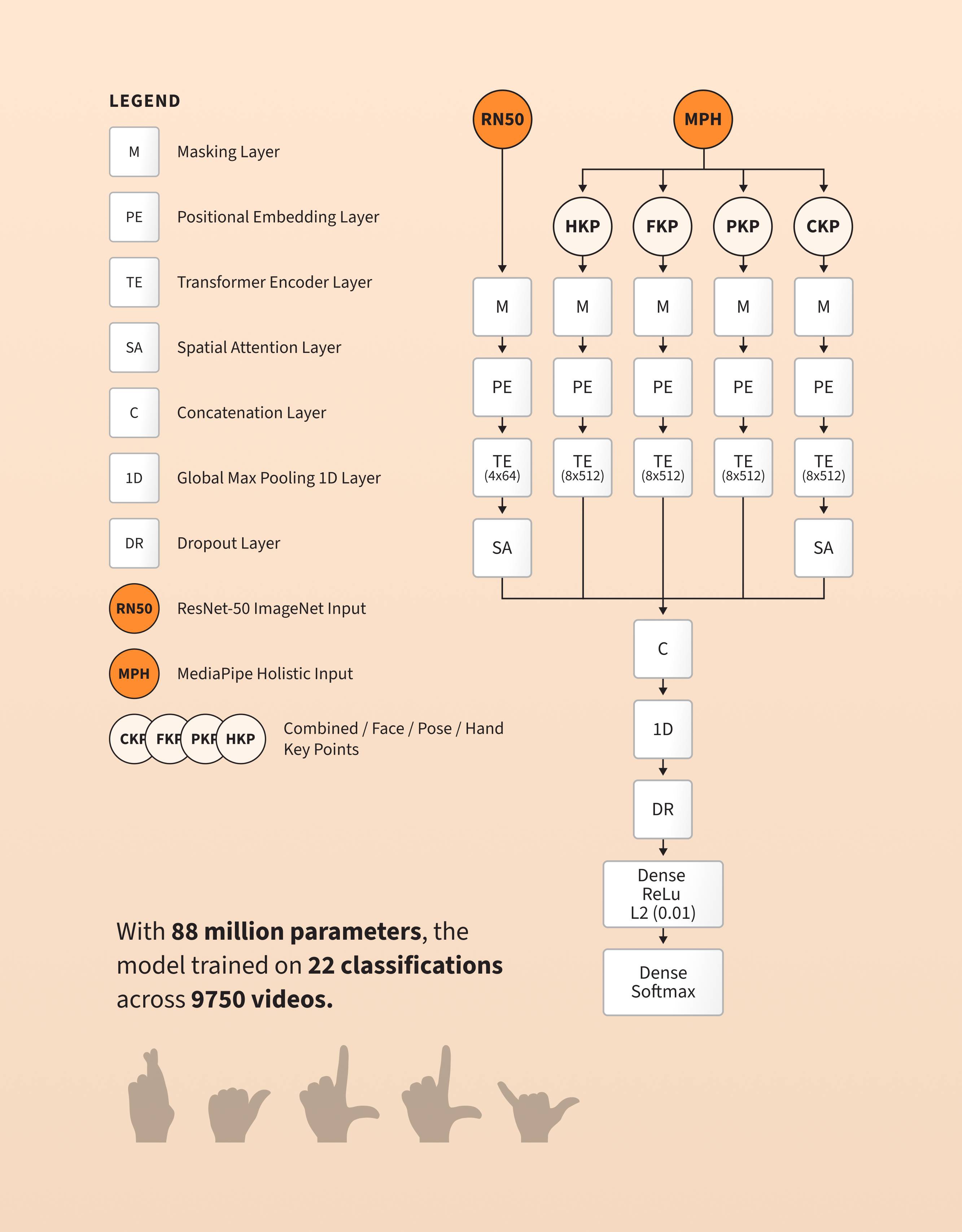
Ra11y introduces a novel encoder-only multimodal transformer that processes skeletal key points and CNN visual features in parallel before combining them across multiple transformer layers. This design improves recognition of complex, dynamic ASL signs and led to an IEEE paper detailing its development.
Training and data augmentation
The dataset was split into training, validation, and unseen test sets. The training data was augmented in two rounds to triple its size, introducing variations like rotations, scaling, shifting, flips, and shears for skeletal keypoints, and random scaling, feature dropout, and noise for CNN features. This approach improved the model's ability to generalize to new signing styles and conditions.


English-to-ASL translation
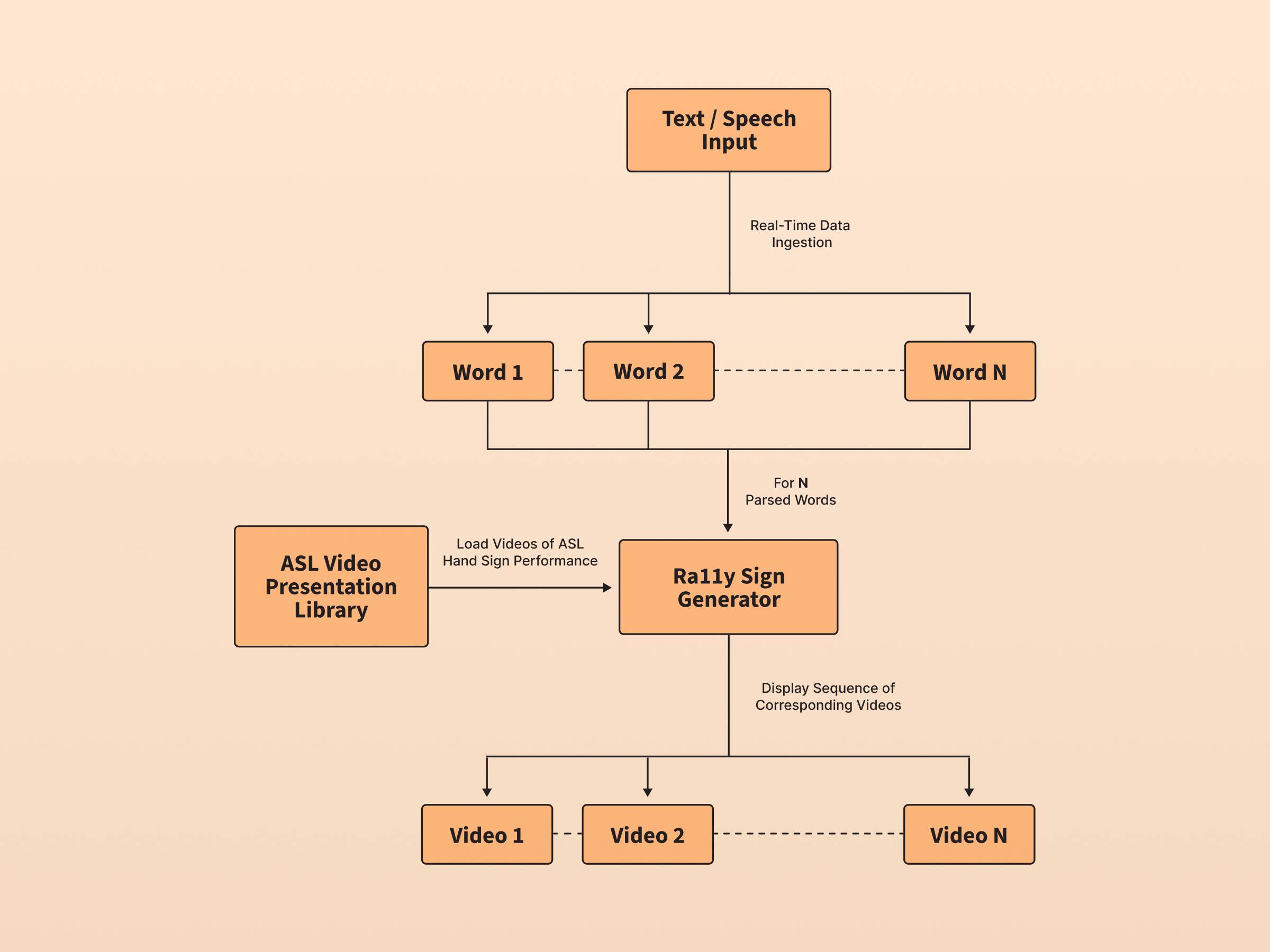
Ra11y generates ASL video sequences from speech, typed text, or prepared scripts. It uses speech recognition to handle spoken input and matches phrases to its sign library. For words not covered, it automatically spells them out letter by letter in ASL, ensuring clear and complete communication for any input type.
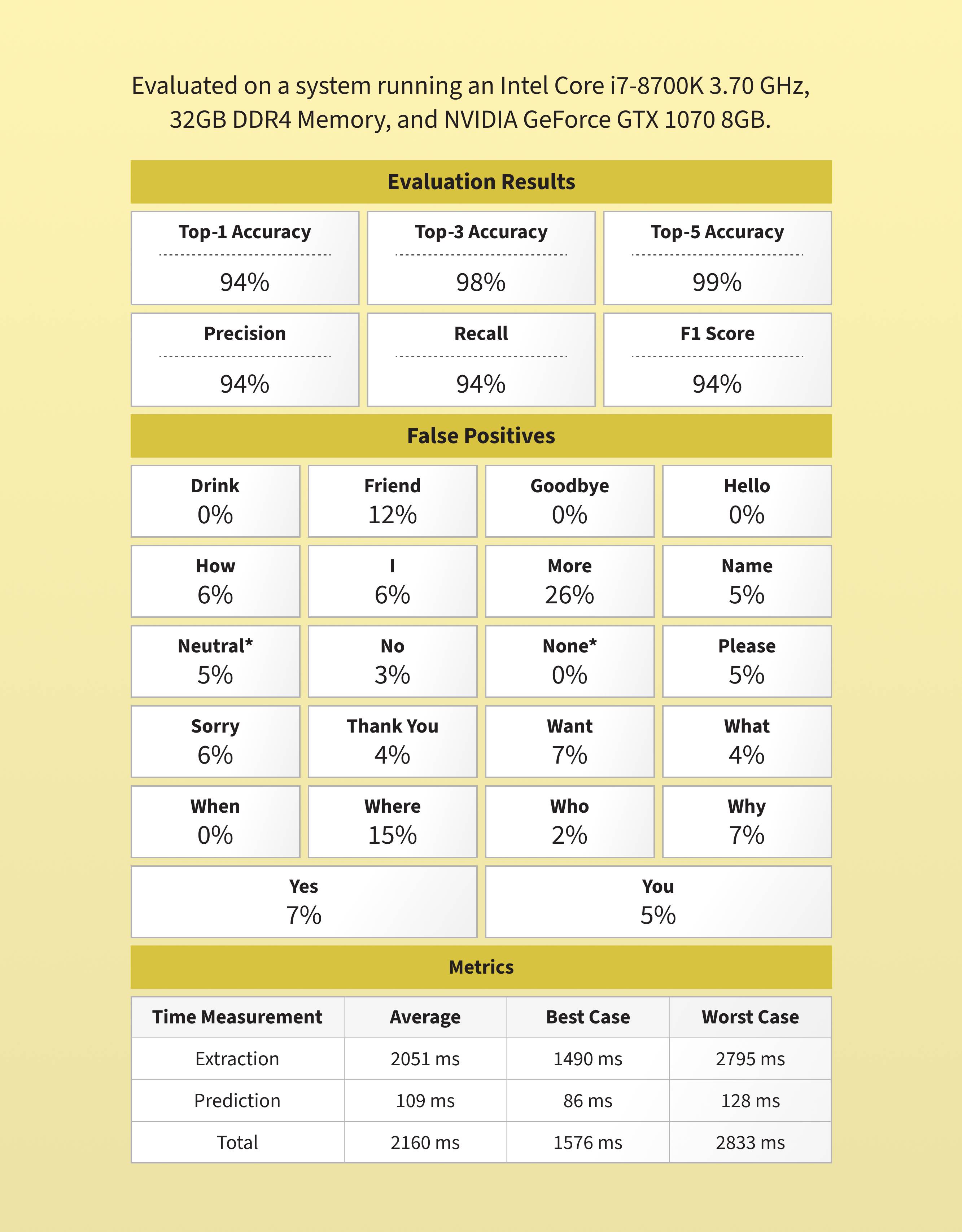
Evaluation results and analysis
Performance was evaluated using metrics like top-K accuracy, precision, recall, and F1 score, demonstrating strong, reliable results.
The project achieved its goal of developing a unique multimodal transformer model as a solid proof of concept for ASL-to-English and English-to-ASL translation, introducing an innovative approach to the field and laying the groundwork for future expansion and real-world use.